
Crimp force monitoring (CFM) has long been the standard for fault detection in wire assemblies. The technique can reliably detect many defects, including wrong strip length, missing strands, wrong wire cross section, wrong terminal, inconsistent terminal material, insulation in the crimp, wrong insertion depth, and wrong crimp height.
In CFM, a piezoelectric sensor measures the force applied to the terminal assembly and the subsequent displacement of the materials. After several reference crimps are made, each subsequent crimp is compared to the known-good reference. If the force and displacement fall within specified tolerances, the crimp is good. If it’s outside those tolerances, it’s bad.
Despite its simplicity and accuracy, CFM has some disadvantages. For one, the technology is expensive. Each crimping press requires its own monitor.

The researchers collected data from a crimping press in operation at a wire harness manufacturing facility. The machine runs daily in multiple shifts. It is equipped with a CFM system. Source: Dongguk University
Another problem is setting the tolerance range. Producing reference samples and collecting data takes considerable time and skill, and the process must be repeated with each new wire and terminal. It’s highly dependent on the skill of the technician.
Scalability is another challenge. If production volumes and variety increase, a CFM system may struggle to maintain efficiency and accuracy.
To address these challenges, CFM systems can be augmented with artificial intelligence (AI). AI continually learns and adapts from real-time data, allowing it to adjust to a broad range of manufacturing processes and external conditions. This adaptability significantly decreases the need for frequent system recalibration. Also, an AI-based system does not require expertise in data processing, making it more accessible.
AI can also enhance the scalability of manufacturing operations by efficiently managing data from multiple production lines and adapting to changes in product types without the need for extensive reconfiguration. This flexibility can help manufacturers respond quickly to market demands and product diversification.

This illustration shows the process of using an AI model for fault detection during a crimping operation. Initially, reference data are manually collected. Then, RSDS is applied to the data to generate synthetic abnormal data by performing upscaling or downscaling on specific regions. The data are then augmented using Laplace distribution to increase the volume of the dataset and improve the training robustness of the model. Finally, the augmented dataset is used to train the AI model, which uses a MLP. Source: Dongguk University
However, before introducing AI into crimping systems, several challenges must be addressed. First, changes in the crimping process can make existing AI models obsolete due to variations in data scales. For example, changing the wire type can alter the overall data scale, rendering previously established models ineffective.
Another challenge is a lack of data points for defective crimps. Such data is important for training AI models. Unpredictable defects can occur, so the more defect data a model has, the more accurate it will be. There are anomaly detection algorithms, such as Isolation Forest, that can be trained solely on normal data to detect unknown defects. But, this may not guarantee sufficient detection accuracy for all potential faults. This makes such algorithms less applicable for quality control in real-world manufacturing.
In response to these challenges, we propose a fault detection system that employs AI with regional selective data scaling (RSDS). RSDS generates synthetic abnormal data from reference data by performing upscaling or downscaling on specific regions of the data. This allows the fault detection system to efficiently train an AI model with a dataset comprised exclusively of normal operational data and still achieve high accuracy in detecting faults.
In this study, a multilayer perceptron (MLP) classification model was trained exclusively on normal data and was able to effectively distinguish between normal and abnormal conditions. To validate the system, 15 unique raw datasets from a real-world wire harness manufacturing facility were collected and tested with four anomaly detection algorithms: Isolation Forest, one-class autoencoders, k-means, and Histogram-Based Outlier Score (HBOS).
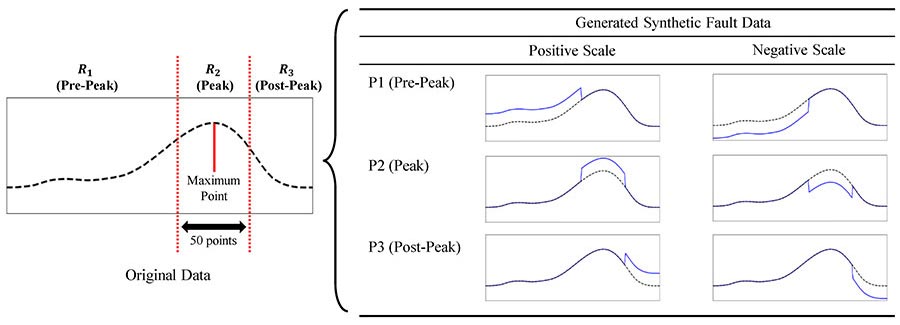
This illustration shows the researchers’ RSDS for generating synthetic abnormal data. This data can help train AI models when there’s a lack of actual data on defects. Rather than uniformly scaling an entire region, this approach divides the region into smaller sections and then selectively applies scaling. Source: Dongguk University
AI for Manufacturing Data
Supervised learning has been used to detect faults in different industrial processes. Its ability to learn from labeled data and predict outcomes makes it a powerful tool for fault detection and classification, particularly in complex manufacturing processes. This approach has been used in sectors like semiconductor manufacturing, where the early detection of faults can offer significant time and cost savings. The technology has also been applied to electric motor manufacturing to optimize processes such as hairpin winding.
Nevertheless, supervised learning requires a significant amount of labeled data for training models, while the process of collecting and labeling data is both time-consuming and costly.
To handle such issues, unsupervised learning and outlier analysis methods can be considered. These methods can extract meaningful features from raw data and efficiently process large volumes of unlabeled data. They are useful for addressing the complexities of manufacturing environments, providing effective diagnostic tools without predefined labels.
However, the utility of these unsupervised learning methods is not without limitations. Generally, the feature selection process may include noise or irrelevant features, which can adversely affect accuracy. It also demands a substantial volume of unlabeled data to achieve a satisfactory level of performance.
To complement such drawbacks, semi-supervised learning techniques can be used. These techniques combine the strengths of both supervised and unsupervised learning by selectively incorporating labeled data from an uncertain unlabeled data pool into the training process. This approach effectively optimizes learning from limited data while further strengthening fault diagnosis by integrating various classifiers, which can help mitigate the risk of incorporating noise or irrelevant features. This can increase the diversity and robustness of the learning process.

This illustration depicts the manufacturing process, where the fault detection system analyzes each dataset sequentially. Source: Dongguk University
Despite these advances, a critical challenge remains in the training model process. For fault detection, these models require data from both normal and abnormal classes for effective training. However, in real-world manufacturing processes, obtaining abnormal data is a challenge due to the unpredictable nature of defects.
Anomaly detection algorithms can address these issues by training models solely with normal data. Numerous anomaly detection techniques have been proposed to classify outliers within normal data. Typically, existing machine learning algorithms are employed for outlier detection. For example, Decision Trees offer a straightforward, rule-based approach to identifying anomalies by detecting deviations from typical patterns. These algorithms enable one-class training by learning the boundaries and characteristics of the normal class from a predominantly normal dataset.
Neural networks can also be used for anomaly detection due to their ability to comprehend complex relationships. For example, autoencoders can effectively use their reconstruction errors to differentiate abnormal status from normal data. Clustering techniques remain powerful for anomaly detection, such as k-means, which groups similar data and highlights outliers in less populated clusters.
Proposed Methodology
To address the limitations of machine learning, anomaly detection algorithms have been proposed to train models using only one-class data. However, in real-world manufacturing, there are few reference data sets available for training an AI model. Models trained solely on a small amount of normal data will show poor performance against diverse and previously unseen anomalies. Additionally, these algorithms can be subject to overfitting, especially when the normal data is not representative of all possible normal behaviors.
Setting up an appropriate threshold to classify anomalies is another challenge. Achieving high accuracy in fault detection requires a careful balance between a model’s sensitivity and specificity.
To develop a practical fault detection system, it’s essential to collect raw data from the actual manufacturing process, instead of theoretical simulations. For our research, we collected data from a crimping press in operation at a wire harness manufacturing facility.
The machine runs daily in multiple shifts and is dedicated to producing wire harnesses for a range of electronic assemblies. It is equipped with a CFM system.

The researchers’ AI system (far right) was better at detecting faulty crimps than other prominent AI models. Source: Dongguk University
Fifteen datasets were collected between April 19 and May 8, 2023. All totaled, 23,383 individual crimp records were collected. The CFM system provides a time stamp for each crimp, as well as a quality label (“good” or “bad”). Some 200 data points for each crimp, with a data point collected every 5 milliseconds. According to the CFM system, 23,286 entries were marked as good, and 97 were labeled as bad. The bad crimps were mostly attributed to issues such as damaged insulation, which leads to exposed wires, and improper crimping, resulting in weak electrical connections that can compromise the overall functionality of the wire harness.
The scales of the datasets, even those collected on the same day, are significantly different, which poses a substantial challenge to the development of a generalized AI model for defect detection. Data collected on April 19, April 26 and May 4 display clear discrepancies. This inconsistency is not just due to the variability in products, but also arises from issues with sensor sensitivity and fluctuations in environmental conditions. Given these variable and inconsistent scales, it is crucial to reset the AI model for each unique manufacturing setup, ensuring accurate defect detection under these diverse and variable conditions.

These graphs display six representative prediction results, all accurately classified. The researchers’ model accurately identified defects of different sizes and shapes. The blue lines represent the researchers’ synthetic data. The green areas are true crimp defects. The red lines are true good crimps. Source: Dongguk University
Proposed Fault Detection System
Considering the constraints of traditional CFM and recognizing the challenges of applying conventional AI to fault detection, this paper presents a new paradigm: a fault detection system based on AI with RSDS. This paradigm solves the challenges caused by limited training data and unpredictable defects by using an anomaly-detection-based algorithm.
In our process, initial reference data is manually collected by an operator. Then, RSDS is applied to the data to generate synthetic abnormal data by performing upscaling or downscaling on specific regions of the data. The data are then augmented using Laplace distribution to increase the volume of the dataset and improve the training robustness of the model. Afterward, an augmented dataset is used to train the AI model of the system, which utilizes an MLP.
An MLP consists of three layers: the input layer receives the initial data, the hidden layers process and transform these data through various computations, and the output layer provides the final result or prediction based on the processed information. Once the model is trained, it begins detecting faults in the remaining upcoming crimping data.
Artificial Intelligence Model
In practical manufacturing scenarios, fault detection systems often classify defects without prior knowledge of defects. For example, CFM systems can accurately detect faults using only 30 data points from normal manufacturing operations, without any defect data. However, training any AI model with only 30 data points is challenging. The reason for this is overfitting, where the model becomes excessively tailored to the limited training data, reducing its ability to detect unseen defects. Moreover, the absence of abnormal data in the initial set might hinder the AI’s ability to recognize and differentiate anomalous patterns from standard ones.

The QpLite2 is a scalable CFM device for ensuring the quality of each crimp. It can be integrated with either single or double-channel benchtop crimp presses. Photo courtesy Komax
Considering these challenges, an MLP is a suitable and technically sound choice for several reasons. First, due to its multifaceted approach, an MLP demonstrates high adaptability against diverse data patterns by modeling both linear and nonlinear relationships through its structured layers of neurons. Each neuron in these layers processes input data.
An MLP needs at least two classes for training, thus requiring the creation of synthetic abnormal data to effectively train the model. Generating and integrating synthetic abnormal data can introduce additional complexities and potential biases into the training process, demanding a careful and strategic approach to ensure genuine and meaningful learning.
A feasible approach might involve upscaling and downscaling of the original data to create synthetic fault data. Implementing upscaling and downscaling randomly on the original data seems like a feasible solution for detecting unexpected defects. However, this technique can complicate the model by necessitating the integration of numerous fault data classes. This increases the model’s structural complexity while prolonging the training.
In contrast, uniformly applying scaling adjusts the entire dataset consistently, potentially simulating various defect scenarios by systematically deviating from the original “normal” manufacturing data. However, uniform scaling across the entire dataset might impede classification performance, as it counters the MLP’s intrinsic learning mechanism.
Given that MLPs learn primarily by adjusting weights during the back-propagation process, uniform scaling, which inherently reduces differences in the data, could adversely impact the model’s ability to effectively differentiate and adjust weights, possibly compromising its predictive accuracy and classification ability.
Consequently, this uniform increment could adversely impact the MLP’s classification performance and predictive accuracy by distorting the relative disparities among each input feature.
Regional Selective Data Scaling addresses these issues. The generated synthetic abnormal data can help to generalize AI models with few reference data points. Rather than uniformly scaling the entire region, this approach divides the region into smaller sections and then selectively applies scaling. In this way, this approach addresses the challenges related to uniform scaling while also allowing for a more systematic simulation of various defect scenarios. RSDS plays a crucial role in creating synthetic abnormal data, allowing models to learn and adapt to different defect types, even when actual defective data are initially unavailable.
Given our strategy for synthetic abnormal data generation, addressing the intrinsic data imbalance, notably with respect to abnormal data, is paramount. Merely replicating synthetic abnormal data might expand the dataset size, but does not introduce the necessary variability for the MLP learning process. This could potentially disrupt the model’s learning during training.
As a result, complexity must be imposed upon the training dataset, ensuring quantity, quality and diversity in the data to facilitate a more sophisticated learning mechanism. To meet this requirement, we implemented a data augmentation technique by introducing noise from the Laplace distribution. This generates a wider range of diverse and challenging samples.

Many fully automatic cutting, stripping and crimping machines are equipped with CFM technology. Photo courtesy Schleuniger
Results and Analysis
To validate our proposed fault detection system, 15 manufacturing datasets were subjected to testing. The datasets were obtained from an actual wire harness manufacturing facility and were collected from April 19 to May 8, 2023. The dataset consists of 24,249 entries—24,152 good crimps and 97 bad crimps.
It’s important to highlight that while our AI model’s findings were not directly compared to the results of the CFM, the data annotated by the CFM proved to be extremely valuable for the purpose of testing our AI model. The CFM system exhibits a commendable level of accuracy. However, it is not exempt from errors. The labels obtained from CFM can be considered reliable with a confidence level of 99 percent, allowing for a minimal 1 percent possibility of inconsistencies.
The experiments were conducted in a specific scenario to simulate real-world manufacturing. At the start, the system begins with the initial dataset and assesses the availability of at least 10 reference data points. It is assumed that the collection and assessment of reference data is performed manually by an operator. However, in the experimental setup, the first 10 data points from the normal label are used to simplify the experimental processes.
After generating synthetic abnormal data from the reference data, an AI model is established. If the system processes all the remaining data, it resets the AI model and moves on to the next dataset, until it processes the last dataset. This approach ensures that each dataset is paired with a dedicated AI model that is carefully calibrated to match its unique characteristics.
Some 60 datasets were generated from the 10 reference data points. These datasets were subsequently expanded to 700 datasets using data augmentation techniques. From the creation of six defective types, seven classes of labels were accordingly established, including the normal class. The training data consisted of a total of 770 fully labeled datasets, each classified into one of the seven classes.
It is worth noting that only 10 out of the 770 datasets were original reference data. To maintain consistency in normalization, the MinMax scaler was employed.
After scaling, the data were used to train an MLP model with 200 input neurons and two hidden layers consisting of 64 and 32 neurons, respectively. The model utilized the ReLU activation function and the “adam” optimization algorithm. An “adaptive” learning rate was employed, with the maximum iteration set at 500. For the evaluation, we chose accuracy and the true-negative rate (TNR) as the main metrics. Accuracy provides a comprehensive assessment of the model’s performance, whereas the TNR specifically evaluates the system’s proficiency in identifying defective items, a critical aspect in the domain of manufacturing quality control.
To evaluate the effectiveness of our method for detecting defects, we tested it against four well-known anomaly detection algorithms: Isolation Forest, autoencoder, k-means, and the Histogram-Based Outlier Score (HBOS).
The Isolation Forest algorithm utilizes tree structures to effectively identify anomalies by focusing on shorter paths in comparison to normal instances. To optimize the performance of the Isolation Forest algorithm, we conducted a grid search to determine the most suitable hyperparameters.
The k-means clustering algorithm, a commonly used unsupervised method in data analysis, was employed to partition the dataset into distinct clusters. In this approach, data points were flagged as anomalies if their distance to the cluster center exceeded a predetermined threshold set at the 95th percentile.

Terminals must be attached to a wire with just the right amount of force. Photo courtesy Partex Marking Systems
Additionally, we implemented an autoencoder, a neural network architecture that is renowned for its ability to perform dimensionality reduction. Anomalies were detected by assessing reconstruction errors that were significantly higher than the threshold set at the 95th percentile of training errors.
Finally, the study utilized the HBOS, a convenient unsupervised technique that calculates outlier scores based on data distributions in a multidimensional space. Our selection comprised a range of methodologies, selected for their widespread use, effectiveness and inclusion of diverse anomaly detection techniques. To maintain a controlled environment, the first 10 data points with a normal labels were used as reference data for all algorithms.
Our proposed system is notable for its exceptional average accuracy of 99.95 percent. Its TNR stood at 85.72 percent, demonstrating its high sensitivity in detecting anomalies.
The HBOS demonstrated an impressive accuracy rate of 99.56 percent. However, the TNR of 0 percent across all datasets indicates potential overfitting and a lack of effectiveness in detecting anomalies.
The k-means algorithm, with 95.39 percent accuracy and 93.44 percent TNR, presents concerns in manufacturing contexts. A difference of 4.5 percentage points may not seem like much, but it implies a substantial number of misclassifications. Moreover, while the k-means’ TNR seems better than our system’s TNR of 85.72 percent, the small sample size of true and false negatives suggests that the apparent advantage may not be significant.
The results for the Isolation Forest and autoencoder algorithms indicate a case of anti-fitting. Specifically, the Isolation Forest showed an average accuracy of 40.42 percent paired with a TNR of 96 percent, while the autoencoder achieved an average accuracy of 68.92 percent with a TNR of 100 percent.
Our study presents a concrete and systematic approach to improving quality control in wiring harness crimping manufacturing by integrating RSDS with AI. This approach utilizes the distinctive capability of RSDS to generate synthetic abnormal data, effectively addressing the challenge of having only limited labeled datasets available for robust AI training. The experimentation conducted on authentic industrial datasets demonstrated both a promising alternative to CFM and its advantage over traditional anomaly detection algorithms. This suggests that the integration of AI can help improve manufacturing quality control.
Editor’s note: This article is a summary of a research paper co-authored by Prashant Kumar and Heung Soo Kim of Dongguk University, and Yonghawn Kim of Sung Chang Co. To read the entire paper, click here.





